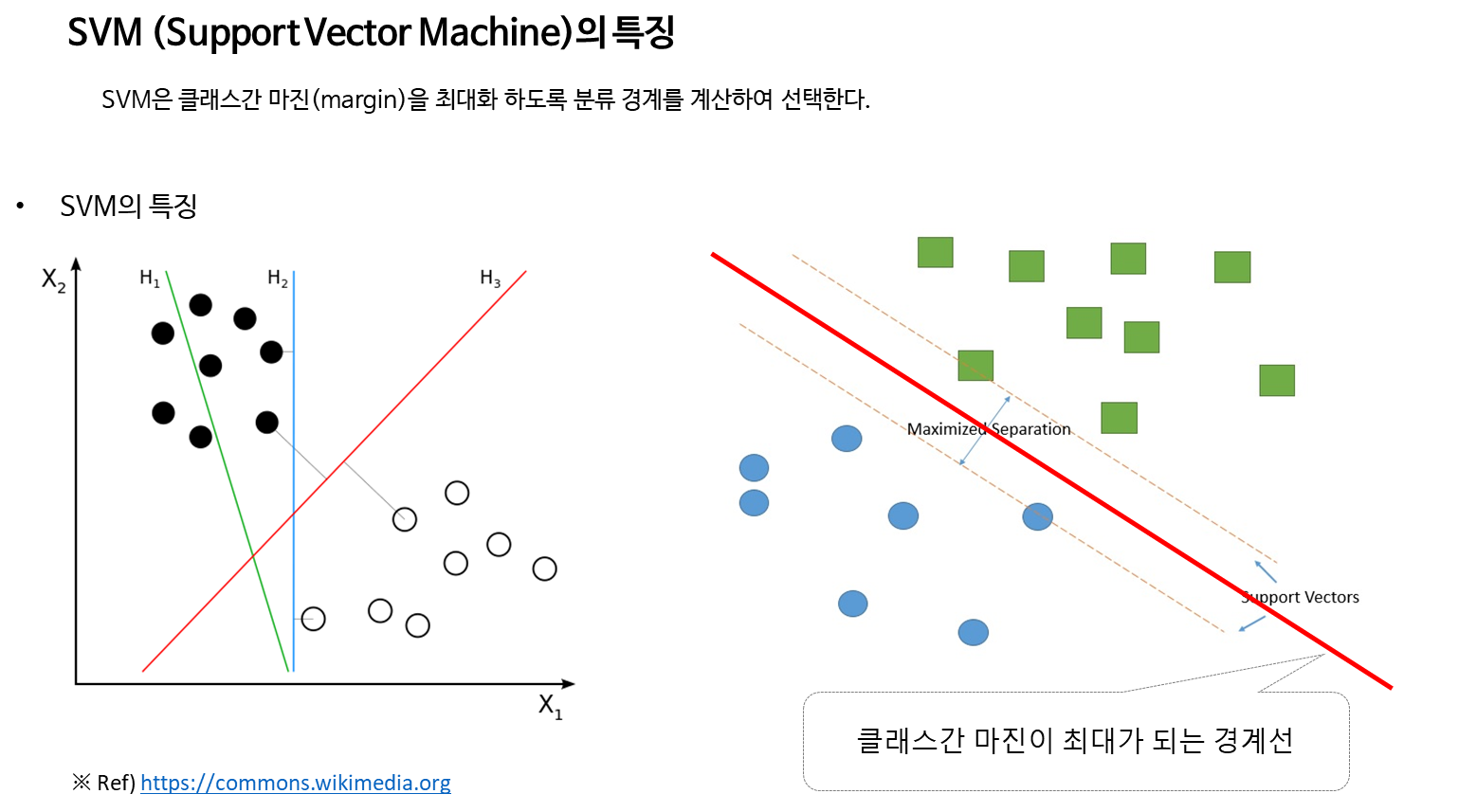
[AI] 인공지능 머신러닝 딥러닝의 개념 비교( SVM 머신러닝, 딥러닝 )

* 머신러닝
1) 내가 알고 있는 (특징과 그결과를 알고 있는) 데이터를 : 학습 데이터
2) 잘 분류할 수 있는 수식의 인자를 : 가중치
3) 컴퓨터가 반복 계산을 통해 계산하는 과정 : 오차를 최소화 하는 방향으로 조절해서.
==> 결과물 : 수식의 인자. (가중치 / Weight)

https://playground.tensorflow.org/
Tensorflow — Neural Network Playground
Tinker with a real neural network right here in your browser.
playground.tensorflow.org
위 사이트에서 뉴럴 네트워크를 본인이 설정하여 점들을 분류해볼 수 있다.



| 구분 | 설명 |
| CNN | - 합성곱신경망, Convolution Neural Network - 데이터의 특징을 추출하여 특징들의 패턴을 파악하는 구조로 이미지 분류에 주로 사용 |
| RNN | - 순환신경망, Recurrent Neural Network - 반복적, 순차적 데이터 학습에 특화된 구조로 시간(순서)에 따라 영향을 받는 데이터의 분석에 주로 사용 |
| YOLO | - You Only Look Once - 단일 스캔 방식으로 영상 내 객체를 식별하는 알고리즘으로 영상 기반 인공지능 서비스에 주로 사용 |
[숙제]
학점 계산 하는 AI 프로그램
국어+수학 / 2 ==> 평균점수
평균점수가
70이상 (A)
40이상 (B)
(C)
--------------------------
String getGrade(국어, 수학)
{
평균 = 국어/수학
if (70<=평균)
return A;
..
..
}
--------------------------
AI / 머신러닝
1) 교수님, 지난 1년간의 학생들 학점 데이터.
--------------------------------------------
KOR MATH GRADE
--------------------------------------------
90 80 A
10 20 C
....
--------------------------------------------
20000건이라는 가정하에,
2) 데이터 전처리
- 이상치, 결측치
===> 학습을 위한 데이터가 준비 되었다.
3) 내가 알고 있는 데이터 (20000건) ; 학습을 위한 15000건 검증(평가)를 위한 5000건.
4) 머신러닝을 위한 모델(SVM, 딥러닝)
5) 15000건(학습)데이터로 학습 ===> 가중치
6) 5000건 (검증)데치터로 정확도 평가 !!! (99.9%)
7) Weight 가중치.
------------------
import random
# 점수를 계산해서 평균에 따른 학점을 반환
# 편의상 A, B, C로 구분함.
def get_grade(kor, math):
mean = int((kor + math) / 2)
grade = "C"
if 70 <= mean:
grade = "A"
elif 40 <= mean:
grade = "B"
return grade
# 20000개 데이터를 만들어 CSV에 기록한다.
fp = open("grade.csv","w",encoding="utf-8")
fp.write("KOR,MATH,GRADE\r\n")
for i in range(20000):
kor = random.randint(10, 100)
math = random.randint(10, 100)
grade = get_grade(kor, math)
fp.write("{0},{1},{2}\r\n".format(kor, math, grade))
fp.close()----------------------

20000개의 데이터 csv 파일 확보.
data review
import matplotlib.pyplot as plt
import pandas as pd
# pands로 csv 파일 읽기
grade = pd.read_csv("grade.csv", index_col=2)
# 그래프로 표시하기
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# Lable 색상 표시하는 함수
def scatter(label_text, color):
b = grade.loc[label_text]
ax.scatter(b["KOR"],b["MATH"], c=color, label=label_text)
scatter("A", "red")
scatter("B", "blue")
scatter("C", "yellow")
ax.legend()
SVM으로 분류하기 (Support Vector Machine)
from sklearn import svm, metrics
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import pandas as pd
# grade가 저장된 CSV 파일 읽기
grade = pd.read_csv("grade.csv")
# 데이터 전처리 (학습을 위하여 데이터를 분리하고 가공-정규화)
label = grade["GRADE"]
kor = grade["KOR"] / 100 # 점수는 최대 100점
math = grade["MATH"] / 100
data = pd.concat([kor, math], axis=1)
# 학습 및 테스트 데이터로 분리
data_train, data_test, label_train, label_test = \
train_test_split(data, label)
# 학습하기
model = svm.SVC()
model.fit(data_train, label_train)
# 테스트 데이터로 에측하기
predict = model.predict(data_test)
# 결과 확인하고 평가하기
ac_score = metrics.accuracy_score(label_test, predict)
cl_report = metrics.classification_report(label_test, predict)
print("Accuracy =", ac_score)
print("Report =\n", cl_report)
딥러닝으로 해보기
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.callbacks import EarlyStopping
import pandas as pd, numpy as np
# grade가 저장된 CSV 파일 읽기
grade = pd.read_csv("grade.csv")
#데이터 전처리 (MLP 학습을 위해 데이터를 가공)
grade["KOR"] /= 100 # 점수는 최대 100점
grade["MATH"] /= 100
X = grade[["KOR", "MATH"]].to_numpy() # 입력데이터 (독립변수)
lable_class = {"A":[1,0,0], "B":[0,1,0], "C":[0,0,1]} # Label (종속변수)
Y = np.empty((20000,3))
for i, j in enumerate(grade["GRADE"]):
Y[i] = lable_class[j]
# 학습 데이터와 테스트 데이터 분할
X_train, Y_train = X[1:15001], Y[1:15001]
X_test, Y_test = X[15001:20001], Y[15001:20001]
# 학습을 위한 모델 구성하기
model = Sequential()
model.add(Dense(512, input_shape=(2,)))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer="rmsprop",
metrics=['accuracy'])
model.summary()
# 모델을 이용한 학습
model.fit(
X_train, Y_train,
batch_size=100,
epochs=20,
validation_split=0.1,
callbacks=[EarlyStopping(monitor='val_loss', patience=2)],
verbose=1)
# 테스트 데이터를 이용한 평가
score = model.evaluate(X_test, Y_test)
print('loss=', score[0])
print('accuracy=', score[1])
# 생성한 모델 이용
X_Data = X[0:10]
result = model.predict(X_Data)
print(result)
predicted = result.argmax(axis=-1)
print(predicted)

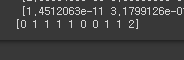
테이블 맵핑 결과 값
A B B B B A A B B C